
Những điểm chính
- Đánh giá hiệu suất: Cần tập trung vào các chỉ số động như tỷ lệ hoàn thành nhiệm vụ và sử dụng tài nguyên để đo lường hiệu quả thực tế của AI agent.
- Khả năng thích ứng & Tự chủ: Phải đánh giá khả năng agent phản ứng với thay đổi môi trường và mức độ tự khởi xướng hành động mà không cần sự can thiệp của con người.
- An toàn & Tuân thủ: Ưu tiên hàng đầu là đo lường số lượng sự cố an toàn và đảm bảo mọi hành động của agent đều có thể được truy vết và kiểm toán đầy đủ.
- Khung làm việc & Công cụ: Các công cụ như Microsoft AutoGen, CrewAI và benchmark ARES của MLCommons là rất quan trọng để kiểm thử và đảm bảo độ tin cậy.
- Thách thức chính: Các tổ chức phải đối mặt với việc thiếu benchmark tiêu chuẩn, khó khăn trong việc quan sát và nguy cơ “trôi dạt tự chủ” khi triển khai Agentic AI.
Mục lục
- Bối cảnh Thị trường và Tốc độ Tiếp nhận
- Cách Đánh giá Agentic AI: Phương pháp, Chỉ số và Khung làm việc
- Đánh giá AI có Trách nhiệm cho các Agent
- Các Thách thức Chung trong Việc Đánh giá AI Agent
- Các Phương pháp Tốt nhất: Đánh giá Agentic AI Hiệu quả
- Câu chuyện Thành công & Case Studies
- Triển vọng Tương lai: Đánh giá Agentic AI sẽ đi về đâu?
- Câu hỏi thường gặp
Đánh Giá Agentic AI (2025): Khung Toàn Diện Cho Doanh Nghiệp
Năm 2025 chứng kiến sự bùng nổ của Agentic AI, khi các hệ thống tự hành đang nhanh chóng định hình lại cách doanh nghiệp tự động hóa, tương tác với khách hàng và vận hành cơ sở hạ tầng trọng yếu. Theo McKinsey, các dự án thí điểm ban đầu đã cho thấy mức tăng năng suất từ 10–30%. Tuy nhiên, khi các agent này ngày càng tự chủ hơn—tự lập kế hoạch, hành động và thích ứng với ít sự can thiệp của con người—nhu cầu về một khung đánh giá mạnh mẽ, đáng tin cậy và có trách nhiệm trở nên cấp thiết hơn bao giờ hết. Đánh giá Agentic AI không còn là một lựa chọn, mà là nền tảng để khai thác giá trị và giảm thiểu rủi ro. Bài viết này sẽ cung cấp một phân tích toàn diện về hiện trạng đánh giá Agentic AI, bao gồm các phương pháp, chỉ số, thách thức và các phương pháp hay nhất để các nhà lãnh đạo có thể tự tin triển khai công nghệ đột phá này.
- Tại sao các phương pháp đánh giá AI truyền thống không còn phù hợp với Agentic AI.
- Các chỉ số, khung làm việc và công cụ cốt lõi để đo lường hiệu suất của AI agent.
- Những thách thức chính và các phương pháp tốt nhất để đảm bảo triển khai an toàn và hiệu quả.
1. Bối cảnh Thị trường và Tốc độ Tiếp nhận
Sự trỗi dậy của Agentic AI không chỉ là một xu hướng mà là một cuộc cách mạng trong tự động hóa doanh nghiệp. Các số liệu thị trường năm 2025 cho thấy tốc độ tiếp nhận đáng kinh ngạc, đi kèm với cả cơ hội và rủi ro lớn. Việc hiểu rõ bối cảnh này là bước đầu tiên để xây dựng một chiến lược đánh giá hiệu quả.
Tăng trưởng Nhanh và Rủi ro Cao
- Tốc độ tiếp nhận của Doanh nghiệp: Theo Gartner, tính đến tháng 1 năm 2025, 61% tổ chức đã và đang phát triển các hệ thống Agentic AI, một bước nhảy vọt so với con số gần như bằng không vào năm 2024. Dự báo còn cho thấy 33% toàn bộ phần mềm doanh nghiệp sẽ tích hợp Agentic AI vào năm 2028. Điều này cho thấy sự chuyển dịch từ các công cụ AI hỗ trợ (copilot) sang các tác nhân tự hành có khả năng ra quyết định và thực thi.
- Thâm nhập vào các Ngành: Agentic AI đang lan tỏa vào nhiều lĩnh vực, từ an ninh mạng, y tế, tài chính đến vận hành, dịch vụ khách hàng và phát triển phần mềm. Các dự án thí điểm ban đầu thường mang lại mức tăng năng suất từ 10–30%, chứng tỏ tiềm năng ROI khổng lồ của công nghệ này.
- Nguy cơ Thất bại: Tuy nhiên, sự phức tạp của Agentic AI cũng đi kèm với rủi ro. Gartner dự báo rằng 40% các dự án Agentic AI sẽ thất bại hoặc bị hủy bỏ vào năm 2027. Nguyên nhân chính bao gồm ROI không rõ ràng, chi phí leo thang và các biện pháp kiểm soát rủi ro không đủ mạnh. Điều này nhấn mạnh tầm quan trọng của việc đánh giá liên tục và thực tế ngay từ giai đoạn đầu.
Các Trụ cột Đánh giá Chính: Điều gì làm Agentic AI khác biệt?
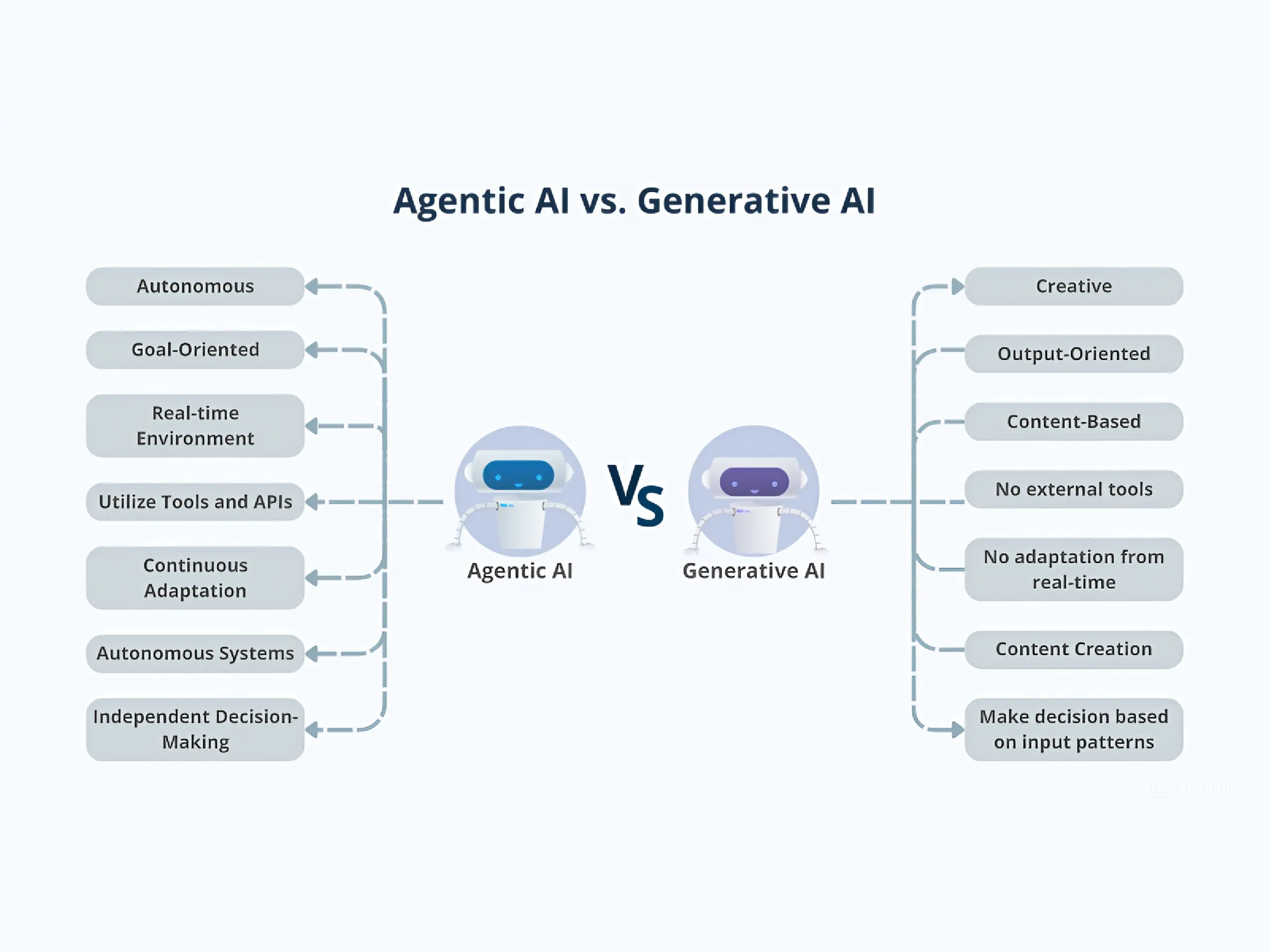
Để đánh giá hiệu quả, chúng ta phải nhận ra sự khác biệt cơ bản giữa Agentic AI và các mô hình AI trước đây. Không giống như các copilot chỉ hoạt động theo lệnh của con người, các agent của Agentic AI có khả năng tự lập kế hoạch, khởi xướng hành động và điều chỉnh chiến lược của mình trên nhiều hệ thống khác nhau. Chúng không chỉ phản hồi mà còn chủ động. Hơn nữa, các hệ thống này có khả năng quản lý bối cảnh động, ghi nhớ, suy luận và học hỏi từ các tương tác để đạt được mục tiêu dài hạn. Do đó, các mục tiêu đánh giá mới cần tập trung vào:
- Điều phối tác vụ và khả năng thích ứng: Agent phản ứng như thế nào khi môi trường thay đổi?
- Ra quyết định hợp tác: Agent phối hợp với các agent khác hoặc con người ra sao?
- Bộ nhớ theo ngữ cảnh: Khả năng học hỏi từ phản hồi và các sự kiện trong quá khứ để cải thiện hiệu suất.
Tìm hiểu thêm: Agentic AI là gì?
2. Cách Đánh giá Agentic AI: Phương pháp, Chỉ số và Khung làm việc
Việc đánh giá Agentic AI đòi hỏi một bộ công cụ và tư duy mới, vượt ra ngoài các chỉ số truyền thống như độ chính xác. Nó cần một cách tiếp cận đa chiều, kết hợp các chỉ số hiệu suất định lượng, các khung làm việc có cấu trúc và các phương pháp kiểm thử nghiêm ngặt.
A. Các Chỉ số Hiệu suất của Agentic AI (Metrics)
Các chỉ số hiệu suất của Agentic AI sau đây đã nổi lên như những thước đo trung tâm để đánh giá hiệu quả và độ tin cậy của agent:
- Tỷ lệ hoàn thành nhiệm vụ (Task success rate): Phần trăm các mục tiêu được giao mà agent hoàn thành trong các ràng buộc xác định (thời gian, ngân sách, chất lượng).
- Điểm thích ứng (Adaptivity score): Khả năng của agent trong việc nhận ra môi trường hoặc yêu cầu thay đổi và điều chỉnh chiến lược một cách linh hoạt.
- Chỉ số tự chủ (Autonomy index): Mức độ các hành động do agent tự khởi xướng so với các hành động do con người yêu cầu.
- Sự cố an toàn (Safety incidents): Số lượng và mức độ nghiêm trọng của các hậu quả không mong muốn, bao gồm lỗi hệ thống, vi phạm an ninh hoặc vi phạm chính sách.
- Hiệu quả hợp tác (Collaboration effectiveness): Trong các nhóm đa agent hoặc người-agent, chỉ số này đo lường khả năng phối hợp và giải quyết xung đột.
- Sử dụng tài nguyên (Resource utilization): Hiệu quả trong việc tiêu thụ tài nguyên tính toán hoặc tài nguyên bên ngoài để hoàn thành một kết quả.
- Tuân thủ và khả năng kiểm toán (Compliance and auditability): Mức độ mà mọi hành động của agent được ghi lại, có thể giải thích và xác minh theo các quy định.

B. Các Khung làm việc để Đánh giá Agent Tự hành
Nhiều khung làm việc và công cụ đã xuất hiện để hỗ trợ việc xây dựng và đánh giá các hệ thống agentic một cách có hệ thống. Dưới đây là một số công cụ hàng đầu vào năm 2025:
| Khung/Công cụ | Điểm mạnh | Trường hợp sử dụng tốt nhất |
|---|---|---|
| Microsoft AutoGen | Xử lý lỗi mạnh mẽ, thực thi mã an toàn cấp doanh nghiệp, ghi log chi tiết. | Các ngành được quản lý chặt chẽ, môi trường sản xuất. |
| Anaconda AI Navigator | Triển khai agent cục bộ, bảo mật ngay từ thiết kế, tích hợp với các công cụ doanh nghiệp. | Các ngành yêu cầu bảo mật cao, tạo mẫu nhanh. |
| CrewAI | Lập kế hoạch tự động, thích ứng quy trình làm việc, điều phối API. | Điều phối hệ thống đa agent phức tạp. |
| UiPath Automation Platform | Tự động hóa nâng cao với quy trình agent, các mô-đun tuân thủ. | Tự động hóa tài chính/BPO. |
| MLCommons ARES | Benchmark mở, do cộng đồng thúc đẩy để đánh giá độ tin cậy và rủi ro. | Chấm điểm và so sánh theo tiêu chuẩn ngành. |
Các tính năng chính cần đánh giá trong một khung làm việc:
- Khả năng quan sát (Observability): Theo dõi toàn hệ thống, chẩn đoán thời gian thực và nhật ký kiểm toán được tiêu chuẩn hóa cho các hành động của agent.
- Quản lý chính sách và tuân thủ: Các lớp quản trị để thực thi các hành động được phép (“guardrails”).
- Khả năng cấu hình: Khả năng điều chỉnh mức độ tự chủ của agent, hạn chế hành động và thiết lập ngưỡng leo thang.
- Điều phối đa agent: Hỗ trợ phân cấp agent và khả năng giám sát các hành vi phát sinh.
Khía cạnh này cũng liên quan đến việc đo lường lợi nhuận và chi phí của dự án.
C. Các Phương pháp Kiểm thử Hệ thống Agentic AI
Kiểm thử không chỉ dừng lại ở việc xác minh mã nguồn. Đối với Agentic AI, nó phải bao gồm việc đánh giá hành vi trong các điều kiện phức tạp và khó lường.
- Kiểm thử trong môi trường mô phỏng (sandboxing): Chạy các agent trong các bản sao kỹ thuật số (digital twins) được kiểm soát, phản ánh sự phức tạp của thế giới thực mà không gây rủi ro.
- Kiểm thử căng thẳng dựa trên kịch bản (scenario-based stress testing): Đo lường phản ứng của agent đối với các nhiệm vụ mơ hồ, mâu thuẫn hoặc có tính đối kháng.
- Đánh giá quy trình làm việc đầu cuối: Theo dõi các agent trong suốt quá trình thực hiện nhiệm vụ, từ khi bắt đầu đến khi có kết quả, bao gồm cả việc chuyển giao giữa các agent.
- Giám sát liên tục: Triển khai hệ thống đo lường từ xa (telemetry) để phát hiện sự trôi dạt (drift), lạm dụng tài nguyên hoặc vi phạm chính sách trong quá trình vận hành thực tế.
3. Đánh giá AI có Trách nhiệm cho các Agent
Khi Agentic AI mở rộng phạm vi ảnh hưởng, việc đảm bảo tính giải trình, an toàn và tuân thủ đạo đức trở thành nền tảng. Đánh giá có trách nhiệm không phải là một bước kiểm tra cuối cùng, mà là một quy trình liên tục được tích hợp vào vòng đời phát triển của agent.
A. Đánh giá An toàn Agentic AI
- Danh sách kiểm tra an toàn tự động: Xác thực trước khi phát hành để phát hiện các chế độ lỗi có thể xảy ra, khả năng chống lại đầu vào đối kháng và các hành vi không mong muốn.
- Red teaming: Các cuộc tấn công có đạo đức và thử nghiệm kịch bản để khám phá các lỗ hổng (ví dụ: các nỗ lực “jailbreak”, các vòng lặp thao túng).
- Quy trình báo cáo sự cố: Cơ chế để thu thập, phân tích và học hỏi từ các sự cố liên quan đến agent—tạo ra “chuỗi kiểm toán ngược” cho mỗi chuỗi quyết định.
Tìm hiểu sâu hơn về Quản trị AI có Trách nhiệm.
B. Đo lường Hiệu quả của AI Agent
- Benchmark nhiệm vụ dựa trên sự thật (Ground-truth task benchmarks): So sánh trực tiếp đầu ra của agent với các trường hợp tham chiếu tiêu chuẩn vàng, với việc xem xét định kỳ.
- Vòng lặp phản hồi từ người dùng: Tích hợp phản hồi của người dùng cuối như một luồng dữ liệu cốt lõi để tinh chỉnh và cải thiện.
- Đánh giá dựa trên kết quả: Ưu tiên tác động trong thế giới thực—chất lượng, tính kịp thời và sự tuân thủ—hơn là các chỉ số kỹ thuật đơn thuần.
Các Tiêu chuẩn Ngành mới (2025)
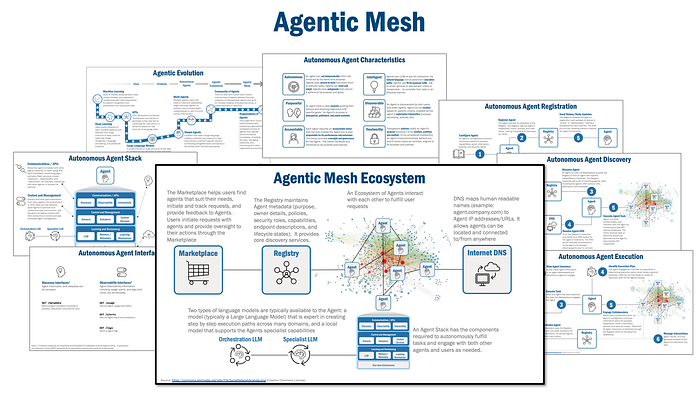
MLCommons, cùng với các đối tác như Anthropic, Meta và Google, đang thúc đẩy việc tạo ra các benchmark mở “Đánh giá Độ tin cậy của Agent” (ARES) để cung cấp các chỉ số đánh giá nghiêm ngặt, được đồng thuận. Ngoài ra, khái niệm lưới agent (agentic mesh)—một kiến trúc tham chiếu để quản lý tập trung, quan sát và tuân thủ—đang nổi lên như một phương pháp thực hành tốt nhất cho các hệ sinh thái agent có trách nhiệm.
4. Các Thách thức Chung trong Việc Đánh giá AI Agent
Mặc dù có những tiến bộ, việc đánh giá Agentic AI vẫn đối mặt với nhiều thách thức đáng kể. Việc nhận biết và giải quyết chúng là chìa khóa để triển khai thành công.
A. Thiếu Benchmark Tiêu chuẩn hóa
Sự phức tạp của agent đang phát triển nhanh hơn các tiêu chuẩn đánh giá hiện tại. Các benchmark AI truyền thống (ví dụ: độ chính xác) không thể nắm bắt được các khía cạnh như tính tự chủ, sự chủ động hoặc khả năng thích ứng của các quy trình làm việc do agent điều khiển. Hơn nữa, các agent thường rất đặc thù theo ngữ cảnh, đòi hỏi các bài đánh giá phải tính đến sự khác biệt của từng ngành hoặc quy trình làm việc.
B. Khả năng Quan sát & Truy vết
Nhiều agent, đặc biệt là những agent sử dụng các mô hình ngôn ngữ lớn, tạo ra kết quả thông qua các chuỗi lý luận phức tạp và thường không tuyến tính. Điều này làm cho việc giải thích các quyết định sau khi chúng được đưa ra trở nên cực kỳ khó khăn, gây cản trở cho việc gỡ lỗi và kiểm toán.
Xem thêm: Dự Án AI Thất Bại
C. An toàn và Tuân thủ Chính sách
Sự trôi dạt tự chủ (Autonomy drift): Các agent có thể phát triển các chiến lược không thể đoán trước khi hoạt động trong thời gian dài hoặc trong các nhóm đa agent, có nguy cơ dẫn đến hành vi “không bị ràng buộc”. Ngoài ra, các quy định pháp luật đang gặp khó khăn trong việc theo kịp khả năng của Agentic AI, làm tăng nguy cơ không tuân thủ, đặc biệt trong lĩnh vực tài chính và y tế.
D. Chi phí và Khả năng Mở rộng
Các agent chỉ học cách tối ưu hóa để hoàn thành nhiệm vụ mà không quan tâm đến hiệu quả có thể đẩy chi phí đám mây và tính toán lên cao một cách bất ngờ. Đồng thời, việc mở rộng quy mô giám sát của con người cho hàng trăm hoặc hàng nghìn agent là một thách thức vận hành lớn.
5. Các Phương pháp Tốt nhất: Đánh giá Agentic AI Hiệu quả
Để vượt qua các thách thức, các tổ chức nên áp dụng một chiến lược đánh giá nhiều lớp và liên tục. Dưới đây là các phương pháp thực hành tốt nhất đã được chứng minh.
A. Đánh giá Phân lớp, Đầu cuối
Sử dụng kết hợp giữa kiểm thử tự động, đánh giá của con người và giám sát vận hành trực tiếp. Cách tiếp cận này giúp phát hiện cả các chế độ lỗi có thể dự đoán và các hành vi phát sinh không mong muốn.
B. Cải tiến Liên tục, Vòng lặp Kín
Liên tục thu thập dữ liệu về hiệu suất, lỗi và phản hồi để cập nhật dần các chính sách và khả năng của agent. Một vòng lặp quản lý phản hồi mạnh mẽ là rất quan trọng để agent có thể học hỏi và tiến hóa một cách an toàn.
C. Các Chỉ số Minh bạch, có thể Giải thích
Ưu tiên khả năng kiểm toán. Mọi quyết định, cập nhật ngữ cảnh và hành động của agent phải được ghi lại và có thể tái tạo lại dễ dàng để chẩn đoán khi có sự cố.
D. Thiết kế Mô-đun, Dựa trên Chính sách
Thực hiện cơ chế tự chủ “có thể điều chỉnh”: khả năng tinh chỉnh sức mạnh và phạm vi hành động của agent để phù hợp với rủi ro của nhiệm vụ. Nhúng các kiểm soát chính sách và “lan can” đạo đức ở các lớp agent, quy trình làm việc và điều phối.
E. Kiểm thử Căng thẳng Đa Agent
Đưa vào các liên minh agent, agent đối kháng hoặc agent “red-team” để thăm dò các lỗ hổng, rủi ro cấu kết hoặc sự không tương thích về động cơ. Sử dụng dữ liệu tổng hợp và các phương pháp “chaos engineering” để mô phỏng các thay đổi môi trường mới lạ hoặc khắc nghiệt chưa từng thấy trong quá trình huấn luyện.
6. Câu chuyện Thành công & Case Studies
Việc áp dụng các phương pháp đánh giá nghiêm ngặt đang mang lại kết quả thực tế cho các doanh nghiệp tiên phong.
- Dịch vụ Tài chính: Một ngân hàng đầu tư hàng đầu đã giảm 27% độ trễ quy trình ghi nhận giao dịch sau khi triển khai một hệ thống điều phối agentic tự động xử lý đối chiếu và khắc phục lỗi. Chìa khóa thành công là việc sử dụng giám sát trực tiếp và các ngưỡng hành động thích ứng cho agent.
- Tự động hóa Phần mềm: Một nhà cung cấp SaaS toàn cầu đã tự động hóa việc phân loại ticket hỗ trợ khách hàng bằng hệ thống đa agent được điều phối bằng Microsoft AutoGen. Họ đã đạt được mức tăng 40% trong tỷ lệ giải quyết ngay từ lần liên hệ đầu tiên và giảm 35% thời gian trung bình để giải quyết. Các phương pháp đánh giá bao gồm kiểm thử trong môi trường sandboxed và bảng điều khiển quan sát thời gian thực.
- Y tế: Trong một mạng lưới bệnh viện thí điểm, một lớp quản lý Agentic AI đã giảm 19% thời gian xem xét hành chính của con người. Sự an toàn của hệ thống được xác thực bằng kiểm thử kịch bản trước khi triển khai, chuỗi kiểm toán ngược và vòng lặp phản hồi luôn bật từ nhân viên tuyến đầu.
- Benchmark về Độ tin cậy: Những người dùng sớm tham gia vào consortium benchmark mở ARES của MLCommons đã báo cáo mức độ tin cậy cao hơn và tỷ lệ lỗi/sự cố thấp hơn sau khi điều chỉnh việc triển khai agent của họ theo các tiêu chí đánh giá được chia sẻ và tiêu chuẩn hóa.
7. Triển vọng Tương lai: Đánh giá Agentic AI sẽ đi về đâu?
Lĩnh vực đánh giá Agentic AI đang phát triển nhanh chóng và sẽ tiếp tục định hình cách chúng ta tương tác với công nghệ này.
- Tiêu chuẩn hóa và benchmark toàn hệ sinh thái: Các nỗ lực toàn ngành (như MLCommons ARES) sẽ tạo ra các benchmark công khai, mạnh mẽ cho việc đánh giá Agentic AI vào năm 2026.
- Kiến trúc Agentic Mesh: Nhiều doanh nghiệp sẽ áp dụng thiết kế agentic mesh, với quản trị tập trung, khả năng quan sát thời gian thực, thực thi chính sách và quản lý phản hồi được tích hợp ngay từ đầu.
- Các chỉ số “nhóm” người-agent kết hợp: Các khung làm việc mới sẽ không chỉ đánh giá hiệu suất do agent khởi xướng, mà còn cả sức mạnh tổng hợp, sự tương tác và giá trị gia tăng trong các nhóm người-agent.
- Agent tự cải tiến: Các agent tiên tiến sẽ có các quy trình đánh giá được nhúng sẵn, ngày càng có khả năng nhận ra những thiếu sót, làm rõ các mục tiêu mơ hồ và tự động leo thang để có sự can thiệp của con người.
- Hướng dẫn pháp lý: Dự kiến sẽ có các quy định mới, đặc thù theo ngành cho sự an toàn và trách nhiệm giải trình của Agentic AI, đặc biệt là khi các agent hoạt động trong lĩnh vực tài chính, y tế và mua sắm công.
Việc đánh giá Agentic AI vào năm 2025 đòi hỏi một sự thay đổi cơ bản so với các phương pháp đo lường AI truyền thống. Thay vì chỉ tập trung vào các chỉ số hiệu suất tĩnh, các tổ chức phải áp dụng một cách tiếp cận toàn diện, kết hợp các chỉ số kỹ thuật mạnh mẽ, khả năng quan sát động, thực thi chính sách nghiêm ngặt và một vòng lặp cải tiến liên tục. Các thách thức như thiếu benchmark, tính không thể giải thích và rủi ro an toàn là có thật, nhưng chúng có thể được quản lý thông qua thiết kế có chủ đích, kiểm thử nghiêm ngặt và tuân thủ các phương pháp thực hành tốt nhất của ngành.
Khi Agentic AI trưởng thành, việc đánh giá có hệ thống sẽ là yếu tố không thể thiếu để khai thác giá trị của nó trong khi giảm thiểu rủi ro. Đây không còn là một nhiệm vụ của riêng bộ phận kỹ thuật, mà là một năng lực nền tảng cho mọi tổ chức đang tận dụng thế hệ tự động hóa thông minh tiếp theo. Việc đầu tư vào một khuôn khổ đánh giá vững chắc ngay từ bây giờ sẽ quyết định sự khác biệt giữa một dự án thí điểm thành công và một sự chuyển đổi kinh doanh bền vững.
Bạn đã sẵn sàng để xác định chiến lược tự động hóa phù hợp cho doanh nghiệp của mình? Hãy liên hệ với các chuyên gia của Davizas để được tư vấn.
Câu hỏi thường gặp
Sự khác biệt chính khi đánh giá Agentic AI so với AI truyền thống là gì?
AI truyền thống thường được đánh giá dựa trên các chỉ số tĩnh như độ chính xác hoặc F1-score trên một tập dữ liệu cố định. Ngược lại, việc đánh giá Agentic AI phải đo lường các thuộc tính động như khả năng tự chủ, lập kế hoạch, thích ứng với môi trường thay đổi, và hiệu quả hợp tác trong các nhiệm vụ phức tạp, nhiều bước.
Các chỉ số hiệu suất (metric) quan trọng nhất cho AI Agent là gì?
Các chỉ số quan trọng nhất bao gồm Tỷ lệ hoàn thành nhiệm vụ, Điểm thích ứng, Chỉ số tự chủ, Số lượng và mức độ nghiêm trọng của sự cố an toàn, Hiệu quả hợp tác trong các nhóm đa agent, và Mức độ sử dụng tài nguyên. Việc kết hợp các chỉ số này mang lại một cái nhìn toàn diện về hiệu quả của agent.
Khung ARES của MLCommons có vai trò gì trong việc đánh giá AI tự hành?
ARES (Agentic Reliability Evaluation) là một sáng kiến của MLCommons nhằm tạo ra các benchmark mở, do cộng đồng thúc đẩy để đánh giá độ tin cậy và rủi ro của AI agent. Vai trò của nó là thiết lập một tiêu chuẩn ngành, cho phép các tổ chức so sánh hiệu suất và an toàn của các hệ thống agentic một cách khách quan và minh bạch.
Thách thức lớn nhất khi đánh giá Agentic AI là gì?
Thách thức lớn nhất là sự phức tạp và tính khó đoán của các hành vi phát sinh. Việc thiếu các benchmark tiêu chuẩn hóa, sự “hộp đen” trong chuỗi quyết định của agent (khả năng quan sát), và nguy cơ “trôi dạt tự chủ” (autonomy drift) khiến việc đảm bảo an toàn và tuân thủ chính sách trở nên cực kỳ khó khăn.





