Những điểm chính
- Metadata tin cậy là nền tảng: Biến metadata từ yếu tố phụ thành trung tâm chiến lược là chìa khóa để xây dựng pipeline dữ liệu hiện đại, đáng tin cậy và minh bạch.
- Tự động hóa là tất yếu: Các phương pháp tốt nhất tập trung vào việc tự động hóa thu thập metadata, truy xuất nguồn gốc (lineage) và kiểm tra chất lượng dữ liệu để phát hiện sớm các vấn đề.
- Quản trị phi tập trung: Mô hình quản trị như data mesh, được hỗ trợ bởi danh mục dữ liệu thông minh, trao quyền cho các nhóm nghiệp vụ và tăng tốc độ triển khai.
- Tăng trưởng thị trường bùng nổ: Thị trường quản lý metadata dự kiến tăng trưởng kép trên 20% mỗi năm, khẳng định đây là một khoản đầu tư chiến lược cho tương lai AI-first.
Mục lục
- Thị trường Quản lý Metadata Bùng nổ: Động lực đằng sau Sự tăng trưởng
- Phương pháp Tốt nhất để Xây dựng Pipeline Dữ liệu Thông minh
- Những Thách thức Phổ biến và Cách Vượt qua
- Câu chuyện Thành công: Giá trị Thực tiễn của Pipeline Thông minh
- Tương lai của Pipeline Dữ liệu: Dự báo đến năm 2035
- Kết luận
- Các câu hỏi thường gặp
Trong bối cảnh bùng nổ dữ liệu hiện nay, các doanh nghiệp đang đối mặt với một nghịch lý: càng có nhiều dữ liệu, việc khai thác giá trị từ chúng càng trở nên phức tạp. Các pipeline dữ liệu truyền thống, vốn đã mong manh, nay lại càng dễ gãy vỡ trước áp lực về khối lượng, tốc độ và sự đa dạng của dữ liệu. Hệ quả là sự thiếu tin cậy vào dữ liệu, các dự án AI/ML đình trệ và các quyết định kinh doanh thiếu chính xác. Giải pháp cho vấn đề này nằm ở một khái niệm mang tính cách mạng: Pipeline dữ liệu thông minh hơn với Metadata tin cậy. Cách tiếp cận này không chỉ đơn thuần là di chuyển dữ liệu từ điểm A đến điểm B, mà còn làm giàu quá trình đó bằng bối cảnh, chất lượng và khả năng truy xuất nguồn gốc. Bằng cách biến metadata từ một yếu tố phụ thành trung tâm của chiến lược dữ liệu, các tổ chức có thể xây dựng những hệ thống vững chắc, tự động và minh bạch, tạo nền tảng cho các sáng kiến MLOps và phân tích tự phục vụ (self-service analytics) quy mô lớn.
- Hiểu rõ tại sao metadata tin cậy là nền tảng cho các pipeline dữ liệu hiện đại.
- Khám phá các phương pháp tốt nhất để triển khai quản lý metadata tự động, quản trị và khả năng quan sát.
- Phân tích những thách thức thực tế và cách vượt qua chúng thông qua các ví dụ thành công.
- Dự báo xu hướng tương lai của pipeline dữ liệu trong kỷ nguyên AI-first.
Thị trường Quản lý Metadata Bùng nổ: Động lực đằng sau Sự tăng trưởng
Sự chuyển dịch sang các pipeline thông minh được phản ánh rõ nét qua tốc độ tăng trưởng chóng mặt của thị trường quản lý metadata doanh nghiệp. Đây không còn là một thị trường ngách mà đã trở thành trọng tâm đầu tư, được thúc đẩy bởi nhu cầu cấp thiết về quản trị dữ liệu và khả năng quan sát. Các báo cáo uy tín cho thấy một bức tranh tăng trưởng đồng thuận. Năm 2024, thị trường này được định giá khoảng 11.23–11.69 tỷ USD và dự kiến sẽ đạt từ 13.11 đến 14.11 tỷ USD vào năm 2025. Động lực chính đến từ áp lực tuân thủ các quy định nghiêm ngặt như GDPR và sự phức tạp của quá trình di chuyển lên môi trường đám mây lai (hybrid cloud). Tuy nhiên, cú nhảy vọt thực sự được dự báo sẽ diễn ra vào cuối thập kỷ. Các chuyên gia dự đoán thị trường sẽ đạt quy mô 35.02–36.44 tỷ USD vào năm 2030, với tốc độ tăng trưởng kép hàng năm (CAGR) ấn tượng từ 20.9% đến 23.68%. Sự tăng trưởng này nhấn mạnh rằng metadata không còn là ‘dữ liệu về dữ liệu’ một cách thụ động, mà là tài sản chiến lược chủ động giúp đảm bảo chất lượng, bảo mật và độ tin cậy trên toàn bộ hệ sinh thái dữ liệu. Các thị trường liên quan cũng cho thấy xu hướng tương tự, với phân khúc danh mục dữ liệu (data catalog) được dự báo tăng trưởng 23.1% CAGR và quản lý dữ liệu AI (bao gồm các giải pháp metadata cho MLOps) đạt 38.27 tỷ USD vào năm 2025. Những con số này khẳng định một điều: đầu tư vào metadata chính là đầu tư vào tương lai của dữ liệu.
Bảng: Dự báo Tăng trưởng Thị trường Quản lý Metadata Doanh nghiệp
Sự khác biệt nhỏ trong các con số dự báo giữa các nguồn xuất phát từ phương pháp luận khác nhau, nhưng xu hướng chung là không thể phủ nhận: một thị trường đang trên đà tăng trưởng bùng nổ trên 20% mỗi năm. Châu Á-Thái Bình Dương nổi lên như một động lực tăng trưởng chính với CAGR lên tới 24.8%, nhờ vào các quy định mới và quá trình chuyển đổi số mạnh mẽ.

| Nguồn | Quy mô 2024 (tỷ USD) | Quy mô 2025 (tỷ USD) | Quy mô 2030 (tỷ USD) | CAGR (2025-2030) |
|---|---|---|---|---|
| 360iResearch | 11.23 | 13.87 | N/A | 23.68% (tới 2032) |
| Mordor Intelligence | N/A | 13.11 | 35.02 | 21.70% |
| Grand View Research | 11.69 | 14.11 | 36.44 | 20.9% |
Phương pháp Tốt nhất để Xây dựng Pipeline Dữ liệu Thông minh
Việc triển khai metadata tin cậy không chỉ là một nâng cấp kỹ thuật; đó là một sự thay đổi về tư duy, biến các quy trình ETL/ELT dễ đổ vỡ thành các hệ thống dữ liệu linh hoạt, có khả năng tự phục hồi và quan sát được. Để đạt được điều này, các tổ chức cần tập trung vào các phương pháp cốt lõi, từ tự động hóa đến quản trị phi tập trung.
1. Tự động hóa Thu thập Metadata và Truy xuất Nguồn gốc (Lineage)
Nền tảng của một pipeline thông minh là khả năng tự động nắm bắt metadata ngay tại thời điểm dữ liệu được tạo ra hoặc biến đổi. Thay vì ghi chép thủ công, hãy sử dụng các công cụ hiện đại có thể theo dõi truy xuất nguồn gốc dữ liệu đáng tin cậy theo thời gian thực trên các môi trường phức tạp như hybrid và multi-cloud. Các dịch vụ liên kết (federated services) giúp hợp nhất các silo metadata, cho phép doanh nghiệp có một cái nhìn toàn cảnh về dòng chảy dữ liệu. Việc tích hợp thu thập metadata trực tiếp vào các công cụ ETL/ELT đảm bảo rằng mọi tài sản dữ liệu đều có nguồn gốc rõ ràng, giúp cải thiện đáng kể độ tin cậy của pipeline. Các dịch vụ như Data Engineering as a Service (DEaaS) có thể giúp triển khai và quản lý các pipeline dữ liệu tự động hóa này.
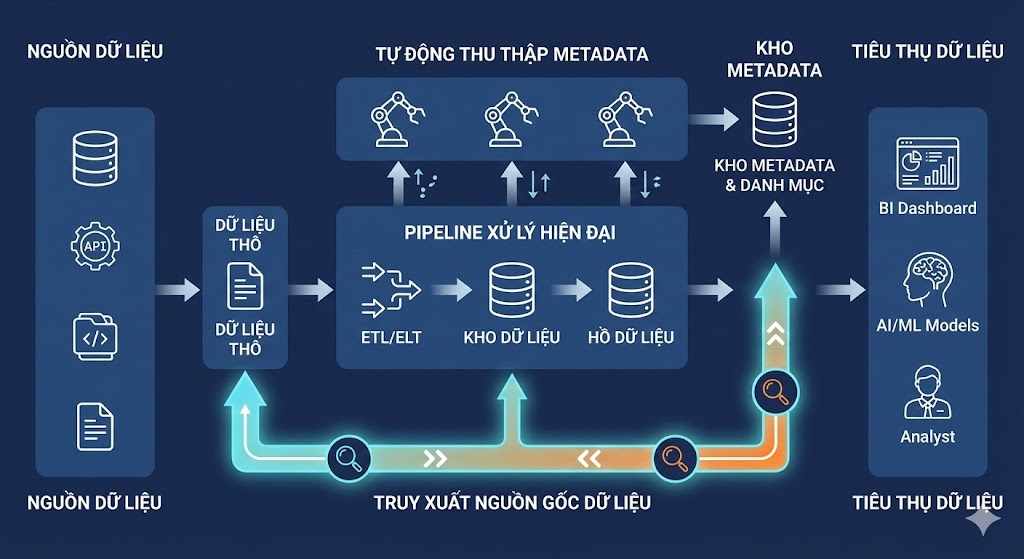
2. Tích hợp Chất lượng và Khả năng Quan sát Dữ liệu
Khả năng quan sát dữ liệu bằng metadata không chỉ là giám sát. Nó bao gồm việc chủ động lập hồ sơ dữ liệu (profiling), phát hiện bất thường và tính điểm chất lượng tự động. Bằng cách nhúng các bước kiểm tra chất lượng vào pipeline, các vấn đề có thể được phát hiện và khắc phục sớm, trước khi chúng ảnh hưởng đến các ứng dụng phân tích hoặc mô hình AI. Ví dụ, các công cụ như CLAIRE Agents của Informatica tự động hóa việc kiểm tra chất lượng và điều phối trong môi trường hybrid. Hơn nữa, việc xây dựng một lớp ngữ nghĩa (semantic layer) giúp cung cấp bối cảnh kinh doanh cho dữ liệu kỹ thuật, cho phép người dùng tự phục vụ một cách an toàn mà không làm mất đi sự kiểm soát về quản trị.
3. Quản trị với Mô hình Phi tập trung
Mô hình quản trị dữ liệu tập trung, từ trên xuống đã không còn phù hợp với tốc độ và quy mô của các tổ chức hiện đại. Thay vào đó, hãy áp dụng các mô hình phi tập trung như data mesh, được hỗ trợ bởi các danh mục dữ liệu thế hệ mới như của Atlan. Cách tiếp cận này trao quyền tự chủ cho các nhóm nghiệp vụ (domain teams) trong việc quản lý dữ liệu của họ, trong khi vẫn duy trì các tiêu chuẩn và chính sách chung. Điều này đặc biệt quan trọng đối với MLOps, nơi các giải pháp metadata cho MLOps cần quản lý các tài sản phức tạp như kho đặc trưng (feature stores) và dữ liệu tổng hợp (synthetic data) một cách linh hoạt.
4. Tận dụng AI để Tối ưu hóa Quản lý Metadata
Bản thân Trí tuệ nhân tạo (AI) cũng là một công cụ mạnh mẽ để cải thiện quản lý metadata. AI có thể được sử dụng để tự động phát hiện, phân loại và gắn thẻ (tagging) dữ liệu, thậm chí đề xuất các quy tắc quản trị. Trong MLOps, danh mục metadata có thể theo dõi đầu vào/đầu ra của mô hình, các phiên bản và hiệu suất, giúp tăng cường khả năng tái tạo và gỡ lỗi. AI cũng hỗ trợ việc ẩn danh hóa dữ liệu nhạy cảm, đảm bảo tuân thủ các quy định về quyền riêng tư mà không cản trở quá trình phân tích. Điều này nhấn mạnh tầm quan trọng của Quản trị AI có Trách nhiệm khi sử dụng AI.
Những Thách thức Phổ biến và Cách Vượt qua
Mặc dù lợi ích của các pipeline thông minh là rất lớn, con đường triển khai không phải lúc nào cũng dễ dàng. Các tổ chức thường phải đối mặt với nhiều rào cản từ kỹ thuật đến văn hóa.
Silo Metadata trong Môi trường Hybrid/Multi-Cloud
Việc di chuyển lên đám mây thường tạo ra các silo metadata mới, làm gián đoạn khả năng truy xuất nguồn gốc dữ liệu đầu cuối. Dữ liệu nhạy cảm có thể vẫn nằm ở on-premise trong khi các ứng dụng phân tích lại chạy trên cloud. Theo Mordor Intelligence, sự phân mảnh này có thể làm giảm 1.6% CAGR của thị trường. Giải pháp: Xây dựng một kiến trúc metadata liên kết (federated) có thể kết nối và hợp nhất metadata từ nhiều nguồn khác nhau, tạo ra một khung nhìn thống nhất.
Bùng nổ Khối lượng Dữ liệu và Lỗ hổng Chất lượng
Khối lượng dữ liệu doanh nghiệp tăng đột biến đòi hỏi các quy trình kiểm tra chất lượng phải diễn ra theo thời gian thực. Các quy trình thủ công không thể đáp ứng, dẫn đến sự xói mòn lòng tin vào dữ liệu. Giải pháp: Tích hợp các công cụ kiểm tra và lập hồ sơ chất lượng dữ liệu tự động vào pipeline để phát hiện sớm các sai lệch.
Rào cản về Quy định và Chủ quyền Dữ liệu
Các quy định như GDPR (Châu Âu) hay DPDPA (Ấn Độ) làm tăng chi phí tuân thủ và đặt ra các yêu cầu nghiêm ngặt về chủ quyền dữ liệu, hạn chế việc di chuyển metadata xuyên biên giới. Điều này có thể kéo lùi 1.2% CAGR. Giải pháp: Sử dụng các giải pháp quản lý metadata hỗ trợ các chính sách dựa trên vị trí địa lý và có khả năng quản lý metadata mà không cần di chuyển dữ liệu gốc. Tìm hiểu sâu hơn về Bảo Mật Dữ Liệu Doanh Nghiệp để đối phó với thách thức này.
Câu chuyện Thành công: Giá trị Thực tiễn của Pipeline Thông minh
Lý thuyết sẽ trở nên vô nghĩa nếu không có những bằng chứng thực tiễn. Các công ty hàng đầu trong nhiều ngành đã chứng minh được giá trị to lớn khi đầu tư vào pipeline dữ liệu dựa trên metadata.
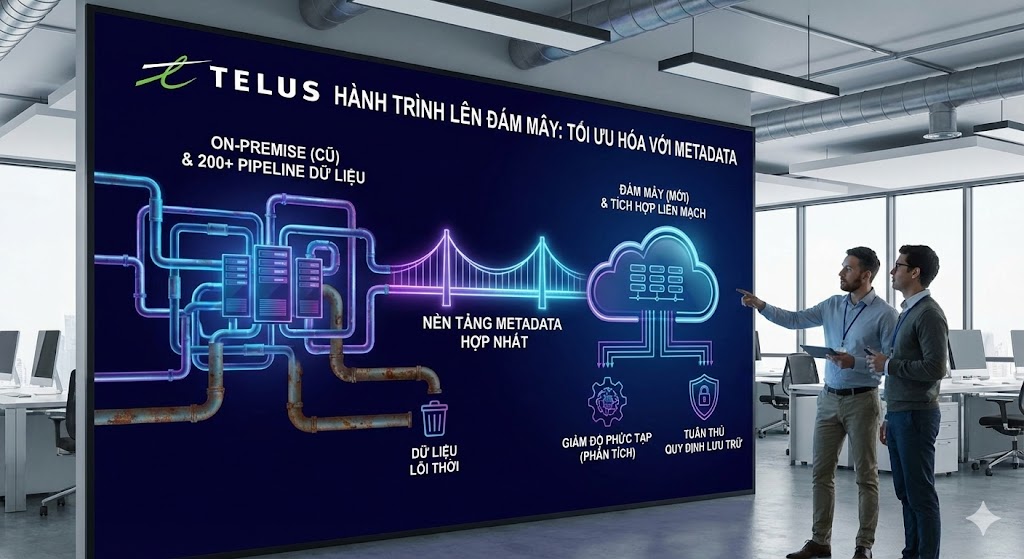
TELUS và Hành trình lên Google Cloud
Khi di chuyển lên đám mây, tập đoàn viễn thông TELUS của Canada đã phải đối mặt với việc tối ưu hóa hơn 200 pipeline dữ liệu. Bằng cách sử dụng một nền tảng metadata hợp nhất, họ đã có thể loại bỏ các dữ liệu lỗi thời, tích hợp liền mạch giữa môi trường on-premise và đám mây, và giảm đáng kể độ phức tạp cho các tải công việc phân tích, đồng thời vẫn đảm bảo các quy định về lưu trữ dữ liệu.
Deutsche Telekom và Capgemini
Gã khổng lồ viễn thông Đức, Deutsche Telekom, đã hợp tác với Capgemini để xây dựng một mô hình metadata tuân thủ chuẩn TMForum. Kết quả là họ đã rút ngắn đáng kể chu kỳ ra mắt sản phẩm mới nhờ vào các dịch vụ hỗ trợ AI và quản trị dữ liệu hiệu quả. Câu chuyện này minh chứng cho vai trò quan trọng của các dịch vụ tư vấn và tích hợp, vốn là phân khúc có tốc độ tăng trưởng nhanh nhất (24.5% CAGR).
Databricks và Quản lý Dữ liệu Petabyte
Nền tảng Databricks đã chứng minh khả năng xử lý hơn 120 petabyte dữ liệu chuỗi thời gian bằng cách sử dụng một hồ dữ liệu (data lake) với metadata tập trung. Điều này giúp tăng cường các pipeline cho dự án AI và hỗ trợ khả năng quan sát dữ liệu bằng metadata ngay trong kiến trúc lakehouse. Những ví dụ này cho thấy ROI rõ ràng, đặc biệt trong các ngành được quản lý chặt chẽ như viễn thông và tài chính, nơi metadata không chỉ giúp tăng hiệu quả mà còn là yếu tố sống còn để đảm bảo tuân thủ.
Tương lai của Pipeline Dữ liệu: Dự báo đến năm 2035
Nhìn về phía trước, vai trò của metadata sẽ ngày càng trở nên trung tâm hơn, định hình nên một thế hệ pipeline dữ liệu mới: tự động, thông minh và liên kết. Các xu hướng chính sẽ định hình tương lai này.
Tự động hóa do AI điều khiển sẽ Thống trị
Việc truy xuất nguồn gốc dữ liệu theo thời gian thực dựa trên đồ thị và gắn thẻ tự động sẽ trở thành tiêu chuẩn. Hơn 70% doanh nghiệp sẽ áp dụng các khung quản trị dữ liệu do AI hỗ trợ. Các danh mục dữ liệu sẽ chuyển hoàn toàn sang mô hình cloud-native, được tăng cường bởi AI để cung cấp các insight chủ động thay vì chỉ là kho lưu trữ thụ động. Đây là một phần của xu hướng lớn hơn hướng tới Thế Giới AI-First.
Kiến trúc Liên kết và Ngữ nghĩa
Lớp ngữ nghĩa cho pipeline dữ liệu sẽ phổ biến rộng rãi để hỗ trợ các kiến trúc phức tạp như data mesh và data fabric trên môi trường multi-cloud. Mặc dù các mô hình hybrid vẫn tồn tại, metadata hợp nhất sẽ giải quyết triệt để vấn đề silo, tạo ra một lớp ngữ nghĩa chung cho toàn bộ doanh nghiệp.
Tích hợp Sâu hơn với MLOps và Khả năng Quan sát
Các giải pháp metadata cho MLOps sẽ mở rộng để quản lý toàn bộ vòng đời mô hình, từ kho đặc trưng, dữ liệu tổng hợp đến giám sát hiệu suất và phát hiện trôi dạt (drift detection). Thị trường quản lý dữ liệu AI được dự báo sẽ đạt 234.95 tỷ USD vào năm 2034, cho thấy sự hội tụ chặt chẽ giữa quản lý dữ liệu và vận hành AI.

Kết luận
Hành trình chuyển đổi từ các pipeline dữ liệu truyền thống sang các hệ thống thông minh hơn được củng cố bởi metadata tin cậy không còn là một lựa chọn, mà là một yêu cầu tất yếu để tồn tại và phát triển trong nền kinh tế số. Metadata đã vượt ra khỏi vai trò kỹ thuật đơn thuần để trở thành tấm vải kết nối, là nền tảng của sự tin cậy trong toàn bộ hệ sinh thái dữ liệu. Bằng cách áp dụng các phương pháp tốt nhất như tự động hóa truy xuất nguồn gốc, tích hợp kiểm tra chất lượng và xây dựng mô hình quản trị linh hoạt, các doanh nghiệp có thể biến những thách thức về khối lượng và độ phức tạp của dữ liệu thành lợi thế cạnh tranh. Các câu chuyện thành công từ TELUS đến Databricks đã chứng minh rằng đầu tư vào metadata mang lại ROI rõ rệt: giảm chi phí, tăng tốc độ đổi mới và quan trọng nhất là xây dựng được niềm tin vào tài sản dữ liệu. Trong tương lai AI-first, những tổ chức tiên phong trong việc xây dựng các pipeline thông minh này sẽ là những người dẫn đầu, có khả năng ra quyết định nhanh hơn, xây dựng các sản phẩm AI tốt hơn và tạo ra giá trị bền vững từ dữ liệu.
Bạn đã sẵn sàng để xác định chiến lược tự động hóa phù hợp cho doanh nghiệp của mình? Hãy liên hệ với các chuyên gia của Davizas để được tư vấn.
Các câu hỏi thường gặp
Metadata tin cậy (trusted metadata) là gì?
Metadata tin cậy là metadata (dữ liệu mô tả dữ liệu khác) được xác minh, chính xác, đầy đủ và có nguồn gốc rõ ràng. Nó cung cấp bối cảnh cần thiết để hiểu về chất lượng, dòng chảy (lineage) và ý nghĩa kinh doanh của dữ liệu, từ đó xây dựng niềm tin cho người dùng và các hệ thống tự động.
Tại sao truy xuất nguồn gốc dữ liệu (data lineage) lại quan trọng đối với AI/ML?
Đối với AI/ML, truy xuất nguồn gốc dữ liệu là cực kỳ quan trọng vì nó cho phép các nhà khoa học dữ liệu theo dõi chính xác dữ liệu nào đã được sử dụng để huấn luyện một mô hình. Điều này cần thiết cho việc tái tạo kết quả, gỡ lỗi mô hình, kiểm tra thiên vị (bias) và đảm bảo tuân thủ các quy định về AI có trách nhiệm.
Làm thế nào để bắt đầu xây dựng một pipeline dữ liệu thông minh?
Hãy bắt đầu bằng cách xác định một hoặc hai pipeline có tác động lớn nhất đến doanh nghiệp, ví dụ như pipeline cung cấp dữ liệu cho báo cáo tài chính hoặc một mô hình AI quan trọng. Sau đó, triển khai thử nghiệm (pilot) một công cụ quản lý metadata hiện đại để tự động hóa việc thu thập metadata và truy xuất nguồn gốc cho pipeline đó. Từ những thành công ban đầu, bạn có thể mở rộng quy mô ra toàn tổ chức.
Khả năng quan sát dữ liệu (data observability) khác gì với giám sát (monitoring)?
Giám sát (monitoring) thường cho bạn biết khi nào một hệ thống bị lỗi. Khả năng quan sát dữ liệu (data observability) đi sâu hơn, giúp bạn hiểu TẠI SAO nó bị lỗi. Nó sử dụng metadata để cung cấp cái nhìn toàn diện về ‘sức khỏe’ của dữ liệu, bao gồm chất lượng, khối lượng, lược đồ (schema) và nguồn gốc, cho phép phát hiện và chẩn đoán vấn đề một cách chủ động.





