Những Điểm Chính
- Tầm quan trọng chiến lược: Metadata đáng tin cậy là nền tảng để đảm bảo chất lượng dữ liệu cho các mô hình AI/ML, giúp tránh khỏi nguyên tắc “rác vào, rác ra”.
- Phương pháp thực tiễn: Triển khai pipeline thông minh đòi hỏi sự kết hợp giữa nền tảng metadata chủ động, khả năng quan sát dòng dữ liệu và các cổng chất lượng (quality gates) tự động.
- Xu hướng tương lai: Thị trường pipeline dữ liệu đang bùng nổ và sẽ tiến tới các hệ thống tự hành, do AI điều khiển, nơi quản trị và độ tin cậy được tự động hóa hoàn toàn vào năm 2030.
Mục Lục
Trong thế giới của Trí tuệ nhân tạo (AI) và Học máy (ML), nguyên tắc “rác vào, rác ra” (garbage in, garbage out) chưa bao giờ đúng hơn thế. Chất lượng của các mô hình AI phụ thuộc hoàn toàn vào chất lượng dữ liệu đầu vào. Tuy nhiên, các pipeline dữ liệu truyền thống thường giống như những đường ống tĩnh, không thể đảm bảo tính toàn vẹn của dữ liệu chảy qua chúng. Đây là lúc “metadata đáng tin cậy” xuất hiện như một yếu tố thay đổi cuộc chơi. Bằng cách làm phong phú các pipeline với dữ liệu về dữ liệu—bao gồm nguồn gốc, chất lượng, và lịch sử sử dụng—chúng ta có thể biến chúng từ những hệ thống thụ động thành các hệ thống thông minh, tự giám sát và tự phục hồi. Bài viết này sẽ đi sâu vào cách xây dựng các pipeline thông minh hơn bằng metadata đáng tin cậy, khám phá bối cảnh thị trường đang bùng nổ, các khái niệm cốt lõi, phương pháp triển khai tốt nhất và những dự báo cho tương lai tự động hóa do AI dẫn dắt.
Bối cảnh Thị trường: Kỷ nguyên Bùng nổ của Pipeline Dữ liệu
Ngành công nghiệp pipeline dữ liệu đang trải qua một giai đoạn tăng trưởng phi mã, được thúc đẩy bởi sự gia tăng của khối lượng dữ liệu, việc áp dụng AI rộng rãi và xu hướng dịch chuyển lên đám mây. Theo nhiều báo cáo, thị trường công cụ pipeline dữ liệu được định giá từ 12.5 đến 14.8 tỷ USD vào năm 2025 và được dự báo sẽ mở rộng một cách đáng kinh ngạc. Các dự báo cho thấy thị trường có thể đạt tới 29.6 tỷ USD vào năm 2029, hoặc thậm chí là 48-52 tỷ USD vào năm 2030-2032, với tốc độ tăng trưởng kép hàng năm (CAGR) ấn tượng từ 19.9% đến 26%. Sự tăng trưởng này phản ánh nhu cầu cấp thiết về các nền tảng có khả năng xử lý dữ liệu với độ trễ thấp và đảm bảo chất lượng vượt trội, đặc biệt là các pipeline tích hợp sẵn metadata đáng tin cậy cho AI. Một phân khúc con quan trọng là các giải pháp quan sát pipeline (data pipeline observability), tập trung vào việc giám sát và đảm bảo chất lượng dữ liệu. Phân khúc này dự kiến đạt 912 triệu USD vào năm 2025 và sẽ tăng lên 2.52 tỷ USD vào năm 2035. Các doanh nghiệp lớn hiện đang chiếm lĩnh thị trường với 68.5% thị phần, đặc biệt trong các lĩnh vực công nghệ và tài chính, nơi việc quản lý pipeline tự động là ưu tiên hàng đầu.
Khái niệm Cốt lõi: Metadata Đáng Tin Cậy là Gì?
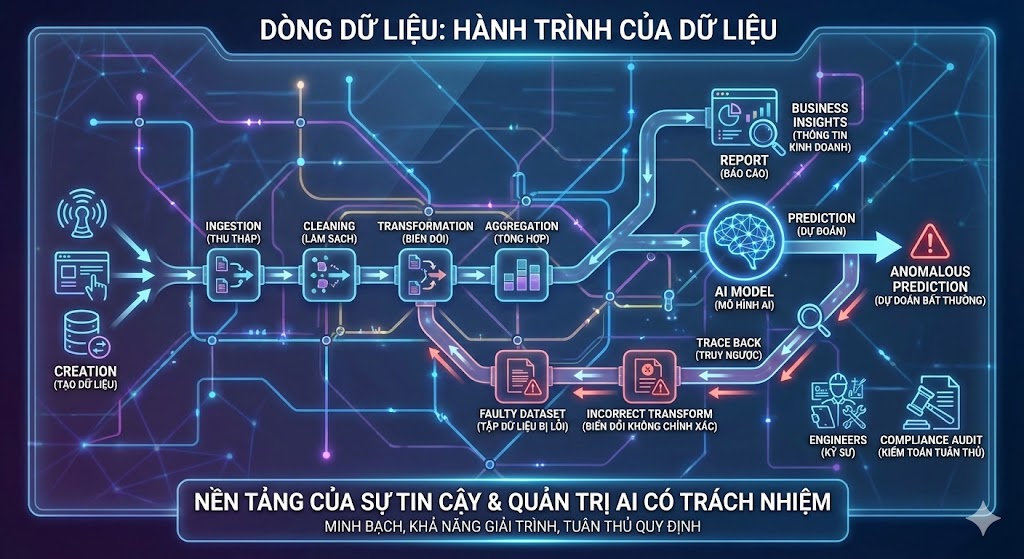
Metadata đáng tin cậy là dữ liệu về dữ liệu đã được làm phong phú và có thể xác minh—chẳng hạn như schema, nguồn gốc (provenance), điểm chất lượng và các mẫu sử dụng. Mục tiêu của nó là xây dựng niềm tin vào kết quả đầu ra của pipeline, điều này đặc biệt quan trọng đối với quản trị dữ liệu cho học máy. Không giống như metadata thụ động, vốn chỉ là các danh mục (catalog) tĩnh, các giải pháp metadata chủ động (active metadata) tự động lan truyền các hiểu biết sâu sắc trên khắp các pipeline, cho phép quản lý tự động và giải quyết vấn đề một cách chủ động. Đây là nền tảng để xây dựng các pipeline dữ liệu mạnh mẽ, nơi dòng dữ liệu (data lineage) có thể theo dõi các phép biến đổi từ nguồn đến nơi tiêu thụ, ngăn chặn triệt để vấn đề “rác vào, rác ra” trong các mô hình AI. Trong thực tế, metadata đáng tin cậy cung cấp sức mạnh cho khả năng quan sát bằng cách gắn cờ các bất thường trong thời gian thực, đảm bảo chất lượng dữ liệu thông qua các quy tắc xác thực tự động và phát hiện sự trôi dạt (drift detection). Đối với các pipeline AI, nó bao gồm các kiểm tra về thiên vị, dấu thời gian về độ tươi mới của dữ liệu và các thẻ tuân thủ, biến metadata thành một “lớp tin cậy” cho sự ổn định của các mô hình ML ở hạ nguồn.
Từ Metadata Thụ động đến Chủ động: Một Sự Thay đổi Mô hình
Metadata thụ động giống như một thư viện cũ: thông tin được lưu trữ nhưng hiếm khi được cập nhật và không tự động tương tác với môi trường xung quanh. Ngược lại, metadata chủ động là một hệ thống thần kinh sống. Nó không chỉ thu thập thông tin về dữ liệu mà còn sử dụng AI để phân tích thông tin đó, đưa ra các đề xuất, cảnh báo về các vấn đề tiềm ẩn và thậm chí kích hoạt các hành động tự động. Ví dụ, một nền tảng metadata chủ động có thể phát hiện sự thay đổi schema ở thượng nguồn và tự động tạm dừng một pipeline ở hạ nguồn để ngăn ngừa lỗi, một khả năng mà các hệ thống thụ động không thể có.

Dòng Dữ liệu (Data Lineage): Bản đồ Dẫn đến Sự Tin cậy
Dòng dữ liệu là bản đồ chi tiết về hành trình của dữ liệu. Nó ghi lại mọi điểm dừng, mọi phép biến đổi và mọi lần sử dụng dữ liệu từ khi nó được tạo ra cho đến khi nó được sử dụng trong một báo cáo hoặc mô hình AI. Một dòng dữ liệu rõ ràng và có thể xác minh là nền tảng của sự tin cậy. Khi một mô hình AI đưa ra một dự đoán bất thường, các kỹ sư có thể sử dụng dòng dữ liệu để nhanh chóng truy ngược lại nguồn gốc của vấn đề—có thể là một tập dữ liệu bị lỗi hoặc một phép biến đổi không chính xác. Điều này không chỉ giúp khắc phục sự cố nhanh hơn mà còn cung cấp khả năng kiểm toán cần thiết cho việc tuân thủ các quy định nghiêm ngặt. Dòng dữ liệu là một thành phần cốt lõi của khuôn khổ Quản trị AI có Trách nhiệm, giúp đảm bảo tính minh bạch và khả năng giải trình.
Các Phương pháp Tốt nhất để Triển khai Pipeline Thông minh
Để xây dựng các pipeline thực sự thông minh, các tổ chức cần áp dụng một cách tiếp cận có cấu trúc, tập trung vào việc vận hành hóa metadata đáng tin cậy. Điều này không chỉ là về việc mua công cụ mới, mà còn là về việc thay đổi văn hóa và quy trình để ưu tiên sức khỏe dữ liệu. Việc triển khai thành công giúp giảm thời gian giải quyết sự cố từ 50-70% bằng cách chuyển từ hoạt động phản ứng sang chủ động.
1. Triển khai Nền tảng Metadata Chủ động
Đầu tư vào các công cụ tự động hóa việc thu thập, làm phong phú và điều phối metadata. Tích hợp các nền tảng này với các danh mục dữ liệu hiện có như Collibra hoặc Alation để tạo ra một nguồn chân lý duy nhất, cho phép các nhóm tự phục vụ khám phá dữ liệu và áp dụng các chính sách quản trị một cách nhất quán.
2. Ưu tiên Dòng Dữ liệu và Khả năng Quan sát
Lập bản đồ các luồng dữ liệu đầu cuối bằng các công cụ quan sát như Monte Carlo hoặc Lightup. Các pipeline hàng đầu đạt được thời gian hoạt động 99.9% nhờ vào việc sử dụng phân tích dự đoán trên các tín hiệu metadata để phát hiện các vấn đề trước khi chúng ảnh hưởng đến người dùng cuối.
3. Tích hợp các Cổng Chất lượng (Quality Gates)
Thực thi chất lượng dữ liệu bằng cách nhúng các điểm kiểm tra dựa trên metadata vào pipeline. Các cổng này có thể tự động xác thực các thay đổi schema, kiểm tra tỷ lệ giá trị null, hoặc thực hiện phân tích thống kê để đảm bảo dữ liệu đáp ứng các tiêu chuẩn trước khi được sử dụng để huấn luyện mô hình ML.
4. Tận dụng Kiến trúc Cloud-Native
Ưu tiên các kiến trúc serverless và dựa trên container, vốn chiếm 62.3% thị phần. Các nền tảng như Apache Airflow hoặc Dagster, khi được kết hợp với các plugin metadata, cung cấp một khuôn khổ linh hoạt và có thể mở rộng để quản lý pipeline tự động trên đám mây. Các kiến trúc Cloud-Native là nền tảng cho các mô hình dịch vụ như Data Engineering as a Service (DEaaS), nơi các pipeline phức tạp được quản lý và cung cấp như một dịch vụ.
5. Thúc đẩy Quản trị Dữ liệu Liên phòng ban
Định nghĩa các chính sách quản trị dữ liệu cho học máy trực tiếp trong các schema metadata. Điều này bao gồm việc thiết lập kiểm soát truy cập, theo dõi dấu vết kiểm toán và gắn thẻ dữ liệu nhạy cảm để đảm bảo tuân thủ các quy định như GDPR và CCPA.
Thách thức và Chiến lược Giảm thiểu
Mặc dù tiềm năng rất lớn, việc triển khai các pipeline dựa trên metadata không phải là không có thách thức. Các tổ chức thường phải đối mặt với các rào cản về công nghệ, quy trình và con người. Tuy nhiên, với chiến lược đúng đắn, những trở ngại này hoàn toàn có thể được khắc phục. Ví dụ, thời gian chết của dữ liệu có thể gây thiệt hại hàng triệu đô la, nhưng các công cụ quan sát dựa trên AI, được dự báo sẽ chiếm 71.6% tăng trưởng của thị trường sau năm 2030, có thể giảm thiểu rủi ro này một cách hiệu quả.
Silo và Metadata Lỗi thời
Thách thức: Các hệ thống cũ thường phân mảnh metadata, dẫn đến dòng dữ liệu không đáng tin cậy và thông tin lỗi thời.
Giải pháp: Áp dụng một lớp metadata chủ động liên kết (federated) có khả năng đồng bộ hóa thông tin trên tất cả các công cụ và làm mới nó trong thời gian thực, tạo ra một cái nhìn thống nhất và chính xác.
Khả năng Mở rộng trong Môi trường Lớn
Thách thức: Sự bùng nổ của dữ liệu từ IoT và AI có thể làm quá tải các pipeline, làm suy giảm chất lượng và hiệu suất.
Giải pháp: Sử dụng các nền tảng truyền dữ liệu (streaming) như Apache Kafka kết hợp với truyền metadata để xử lý khối lượng lớn và duy trì chất lượng dữ liệu ngay cả khi đang di chuyển.
Thiếu hụt Kỹ năng cho Kỹ sư Dữ liệu
Thách thức: Việc quản lý metadata phức tạp đòi hỏi chuyên môn cao mà không phải lúc nào cũng có sẵn.
Giải pháp: Các công cụ low-code và thiết kế được hỗ trợ bởi AI có thể hạ thấp rào cản gia nhập, cho phép nhiều người hơn tham gia vào việc xây dựng và duy trì các pipeline chất lượng cao.
Dự báo Tương lai: Pipeline Tự hành vào năm 2030
Đến năm 2030-2035, các pipeline thông minh được điều khiển bởi metadata đáng tin cậy sẽ trở thành tiêu chuẩn, được thúc đẩy bởi sự hội tụ sâu sắc với AI. Thị trường công cụ được dự báo sẽ vượt 48 tỷ USD vào năm 2030, làm mờ ranh giới giữa quan sát dữ liệu và MLOps.
Pipeline AI-Native Tự hành
Các pipeline sẽ tiến hóa thành các hệ thống tự trị. Generative AI sẽ tự động tạo ra các quy tắc về dòng dữ liệu và chất lượng, trong khi các mô hình dự đoán sẽ tự động định tuyến lại dữ liệu xấu hoặc tối ưu hóa luồng công việc để giảm chi phí. Các hệ thống này được dự báo sẽ chiếm hơn 71% sự tăng trưởng của thị trường quan sát. Việc áp dụng các pipeline AI-native sẽ là một phần không thể thiếu trong Chiến lược AI cho Doanh nghiệp Việt muốn dẫn đầu thị trường.
Sự Tin cậy Thúc đẩy bởi Quy định
Các quy định về AI ngày càng nghiêm ngặt, như AI Act của Châu Âu, sẽ bắt buộc phải có dòng dữ liệu có thể kiểm chứng. Điều này sẽ thúc đẩy việc áp dụng các công cụ quản trị dựa trên metadata. Dự báo đến năm 2032, 80% các pipeline sẽ được nhúng metadata quản trị theo mặc định.
Dân chủ hóa Quản lý Metadata
Việc quản lý metadata sẽ không còn là lĩnh vực của riêng các kỹ sư dữ liệu chuyên sâu. Các giao diện no-code và trực quan hóa sẽ cho phép các nhà phân tích kinh doanh và các bên liên quan khác tham gia vào việc định nghĩa và duy trì chất lượng dữ liệu, dân chủ hóa quyền truy cập và trách nhiệm.
Việc chuyển đổi từ các pipeline dữ liệu tĩnh, thụ động sang các hệ thống thông minh, tự nhận thức được củng cố bởi metadata đáng tin cậy không còn là một lựa chọn xa xỉ—đó là một mệnh lệnh chiến lược.
Trong bối cảnh thị trường đang tăng trưởng với tốc độ hơn 20% mỗi năm, các tổ chức không đầu tư vào sức khỏe dữ liệu sẽ nhanh chóng bị tụt lại phía sau. Bằng cách áp dụng các nguyên tắc của metadata chủ động, dòng dữ liệu minh bạch và các cổng chất lượng tự động, các doanh nghiệp có thể xây dựng nền tảng vững chắc cho các sáng kiến AI/ML của mình. Điều này không chỉ giúp giảm thiểu rủi ro và chi phí vận hành mà còn mở ra những cơ hội mới để đổi mới và tạo ra lợi thế cạnh tranh. Tương lai của dữ liệu không chỉ nằm ở khối lượng, mà còn ở sự tin cậy. Các pipeline thông minh là con đường để đạt được sự tin cậy đó ở quy mô lớn.
Bạn đã sẵn sàng để xác định chiến lược tự động hóa phù hợp cho doanh nghiệp của mình? Hãy liên hệ với các chuyên gia của Davizas để được tư vấn.
Câu hỏi thường gặp
Tại sao metadata đáng tin cậy lại quan trọng cho AI/ML?
Metadata đáng tin cậy là yếu tố sống còn đối với AI/ML vì nó giải quyết trực tiếp vấn đề ‘rác vào, rác ra’. Nó đảm bảo rằng dữ liệu được sử dụng để huấn luyện các mô hình là chính xác, đầy đủ và không thiên vị. Bằng cách cung cấp dòng dữ liệu rõ ràng và các kiểm tra chất lượng tự động, nó giúp xây dựng các mô hình AI đáng tin cậy, chính xác và có thể giải thích được.
Metadata chủ động khác gì với metadata thụ động?
Metadata thụ động là một bản ghi tĩnh về dữ liệu, giống như một danh mục trong thư viện. Ngược lại, metadata chủ động là một hệ thống động, sử dụng AI để liên tục thu thập, phân tích và hành động dựa trên metadata. Nó có thể đưa ra các đề xuất, tự động hóa các quy trình quản trị và dự đoán các vấn đề tiềm ẩn trong pipeline, trong khi metadata thụ động chỉ đơn thuần là để tra cứu.
Những lợi ích kinh doanh chính của việc đầu tư vào pipeline dữ liệu thông minh là gì?
Đầu tư vào pipeline dữ liệu thông minh mang lại ROI đáng kể thông qua ba lợi ích chính: 1) Giảm chi phí vận hành bằng cách giảm 50-70% thời gian chết của dữ liệu và tự động hóa việc khắc phục sự cố. 2) Tăng doanh thu bằng cách cải thiện độ chính xác và hiệu suất của các mô hình AI, dẫn đến các quyết định kinh doanh tốt hơn. 3) Giảm thiểu rủi ro bằng cách đảm bảo tuân thủ quy định thông qua quản trị và dòng dữ liệu tự động.





